stac-geoparquet
Pete Gadomski
2025-06-06
What the STAC?
STAC is the map to your data.
— Howard Butler

STAC-as-a-service
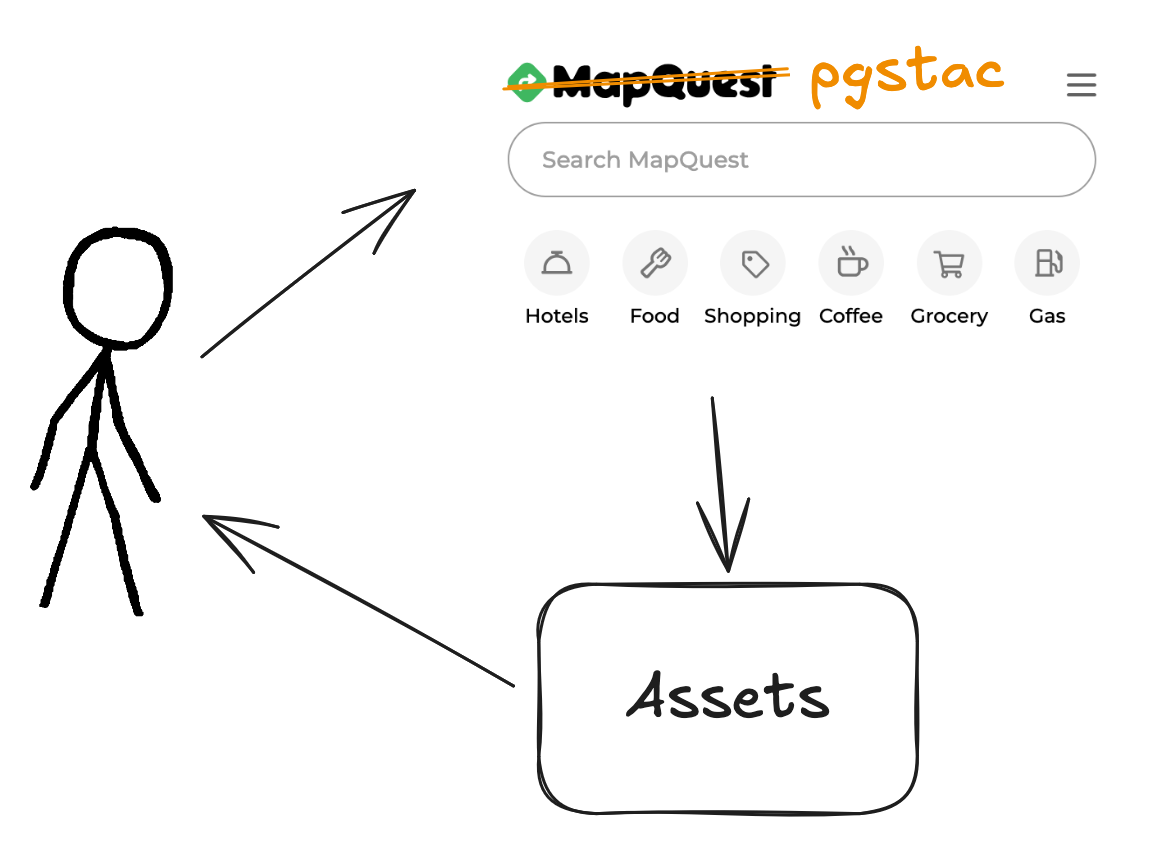
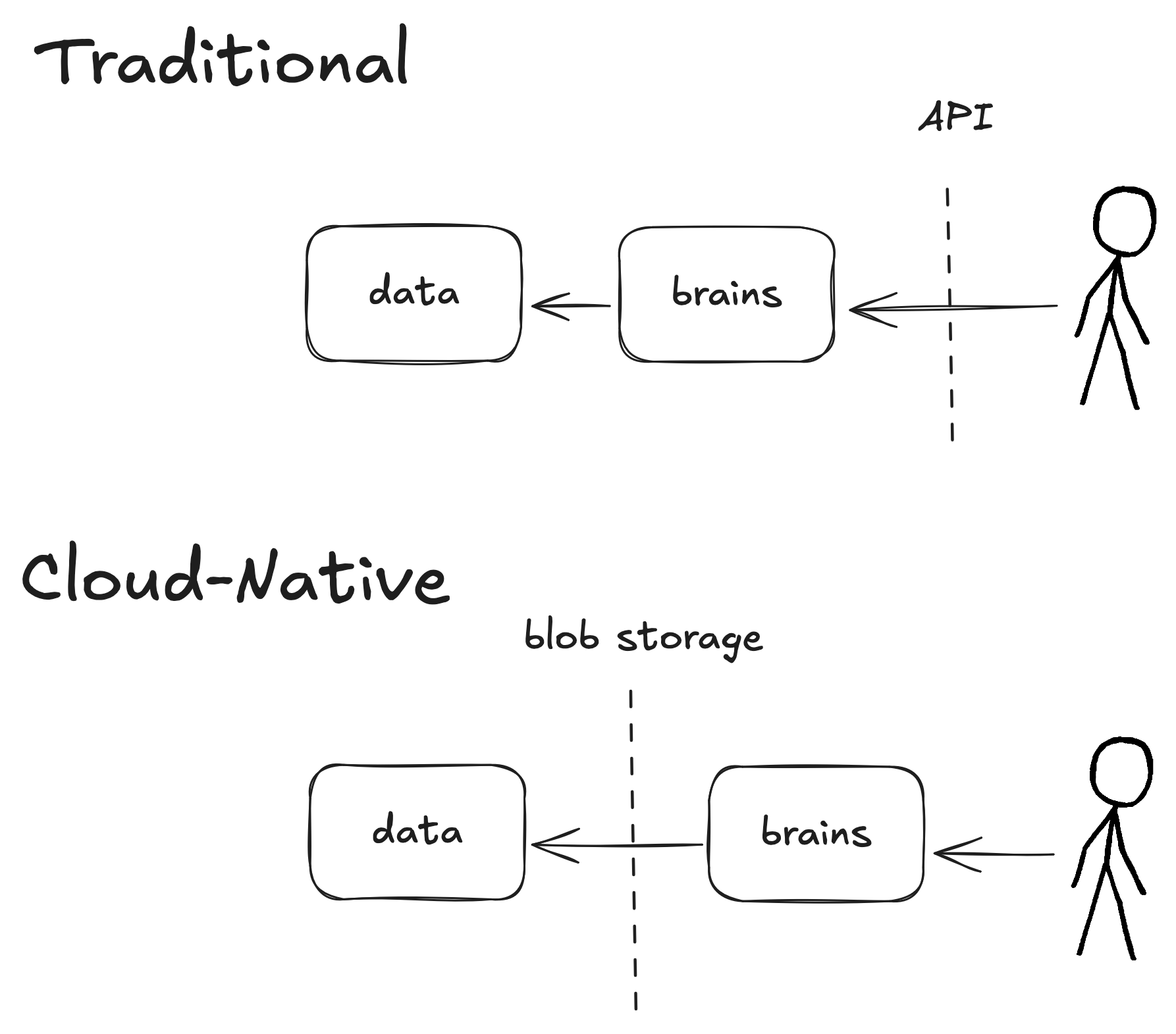
STAC-as-data

USMC Archives from Quantico, USA, CC BY 2.0, via Wikimedia Commons
.jpg){kind=link}
stac-geoparquet


How do?
$ python -m pip install stac-geoparquet
import stac_geoparquet.arrow
import pyarrow.parquet
infile = "items.ndjson"
outfile = "items.parquet"
stac_geoparquet.arrow.parse_stac_ndjson_to_parquet(infile, outfile)
table = pyarrow.parquet.read_table(outfile)
items = stac_geoparquet.arrow.stac_table_to_items(table)
How do?
$ python -m pip install rustac
import rustac
infile = "items.ndjson"
outfile = "items.parquet"
items = await rustac.read(infile)
await rustac.write(outfile)
items = await rustac.read(outfile)
$ rustac translate items.ndjson items.parquetWhat do?
$ gpq describe items.parquet
╭────────────────────┬────────┬─────────────────────────────────────────────────────────────────────────────── ≈
│ COLUMN │ TYPE │ ANNOTATION ≈
├────────────────────┼────────┼─────────────────────────────────────────────────────────────────────────────── ≈
│ stac_version │ binary │ string ≈
│ stac_extensions │ │ list ≈
│ id │ binary │ string ≈
│ instruments │ │ list ≈
│ license │ binary │ string ≈
│ links │ │ list ≈
│ assets │ │ group ≈
│ collection │ int32 │ null ≈
│ datetime │ int64 │ timestamp(isadjustedtoutc=true, timeunit=milliseconds, is_from_converted_type= ≈
│ start_datetime │ int64 │ timestamp(isadjustedtoutc=true, timeunit=milliseconds, is_from_converted_type= ≈
│ end_datetime │ int64 │ timestamp(isadjustedtoutc=true, timeunit=milliseconds, is_from_converted_type= ≈
│ title │ binary │ string ≈
│ created │ int64 │ timestamp(isadjustedtoutc=true, timeunit=milliseconds, is_from_converted_type= ≈
│ oam:producer_name │ binary │ string ≈
│ oam:platform_type │ binary │ string ≈
│ gsd │ double │ ≈
│ providers │ │ list ≈
│ bbox │ │ group ≈
│ geometry │ binary │ ≈
│ │ │ ≈
├────────────────────┼────────┴─────────────────────────────────────────────────────────────────────────────── ≈
│ Rows │ 17669 ≈
│ Row Groups │ 1 ≈
│ GeoParquet Version │ 1.1.0 ≈
╰────────────────────┴──────────────────────────────────────────────────────────────────────────────────────── ≈
stac-geoparquet-viewer
TODO
stac-geoparquet-pmtiles
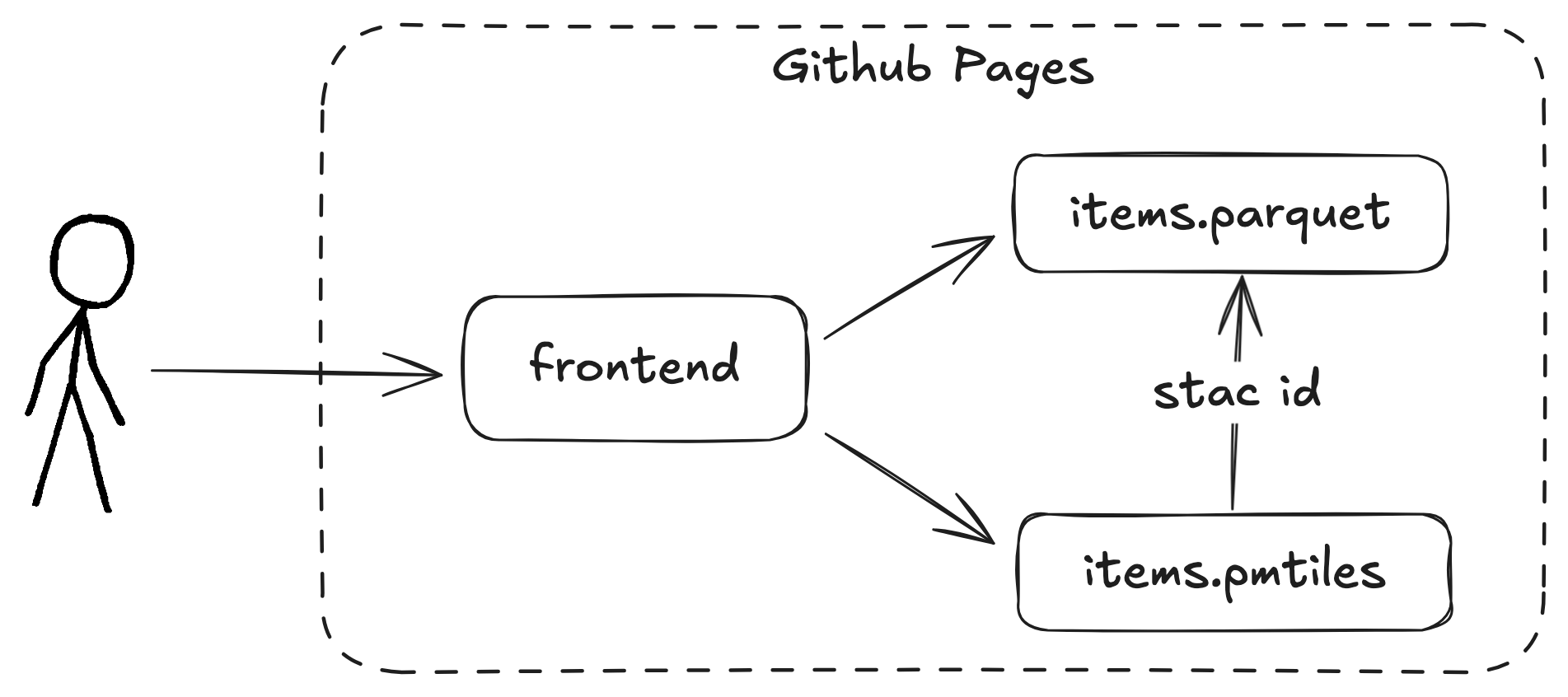
Why do?
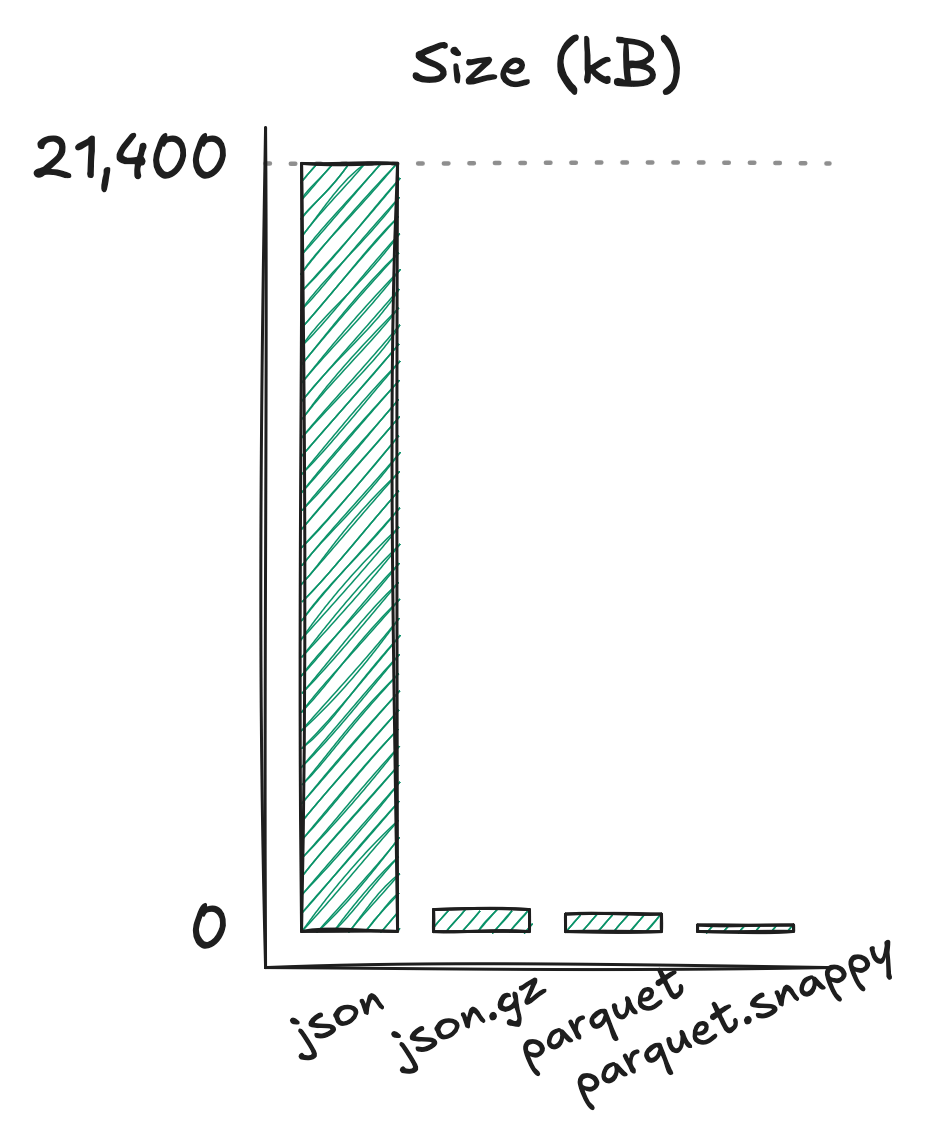
| Format | Size |
|---|---|
| json | 21 MB |
| json.gz | 614 kB |
| parquet | 488 kB |
| parquet (compressed) | 179 kB |
1000 sentinel-2 items
duckdb 🦆
D select count(*)
from read_parquet('s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned/**/*.parquet');
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 9907260 │
│ (9.91 million) │
└────────────────┘
D select count(*)
from read_parquet('s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned/**/*.parquet')
where percent_valid_pixels=100;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 39696 │
└──────────────┘
STAC API search
import cql2
import rustac
href = "s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned/**/*.parquet"
cql2_json = cql2.parse_text("percent_valid_pixels=100").to_json()
items = await rustac.search(href, filter=cql2_json)
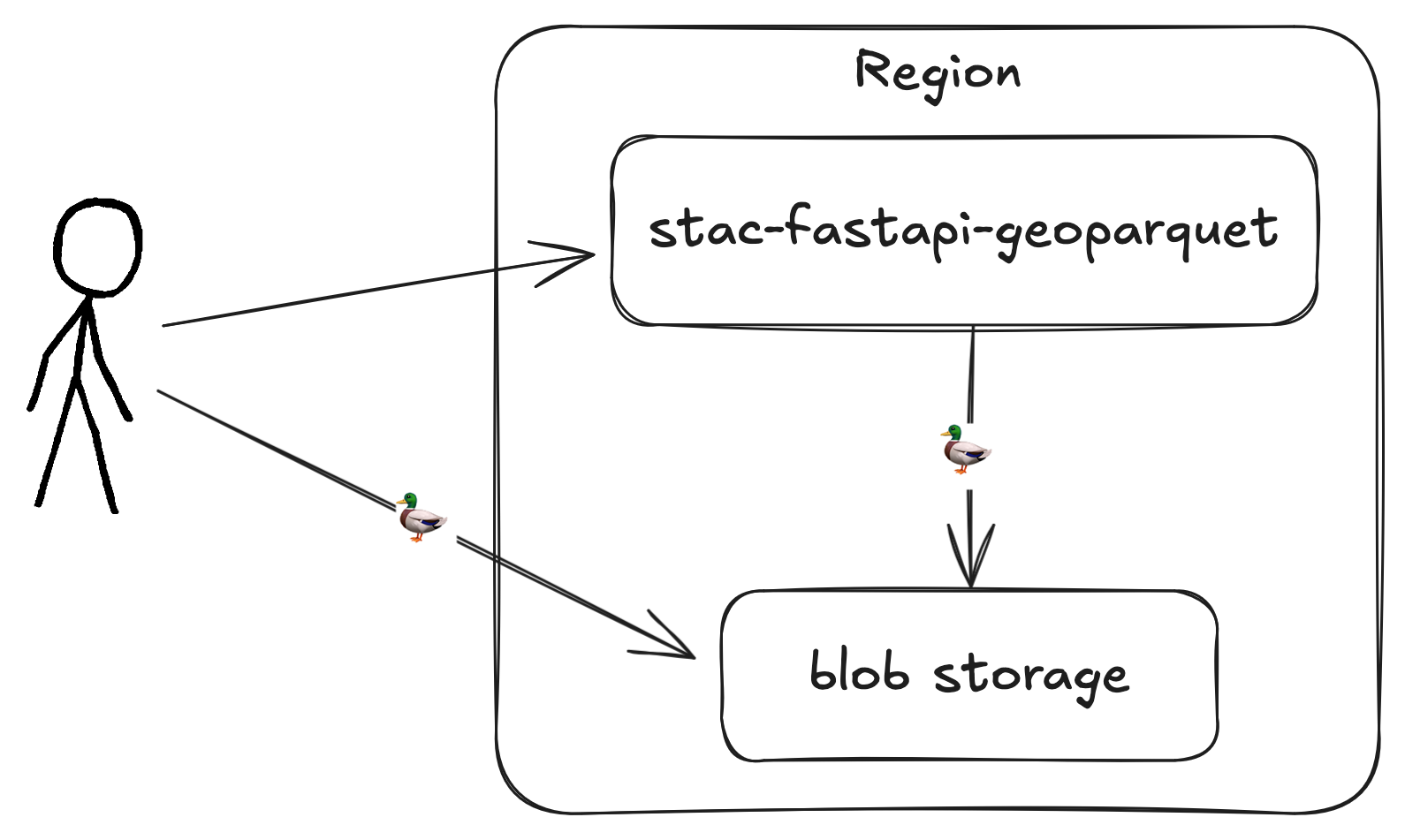
stac-fastapi-geoparquet
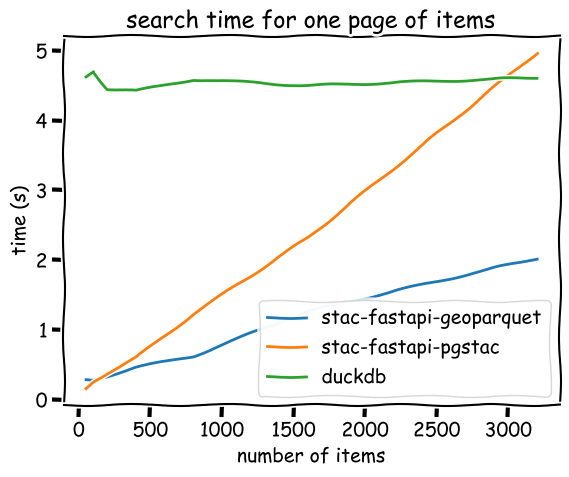
Search performance
Needle in a haystack
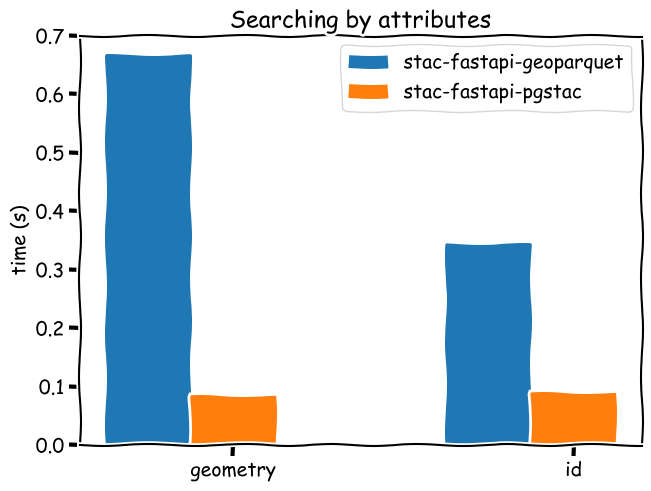
* worse for larger datasets
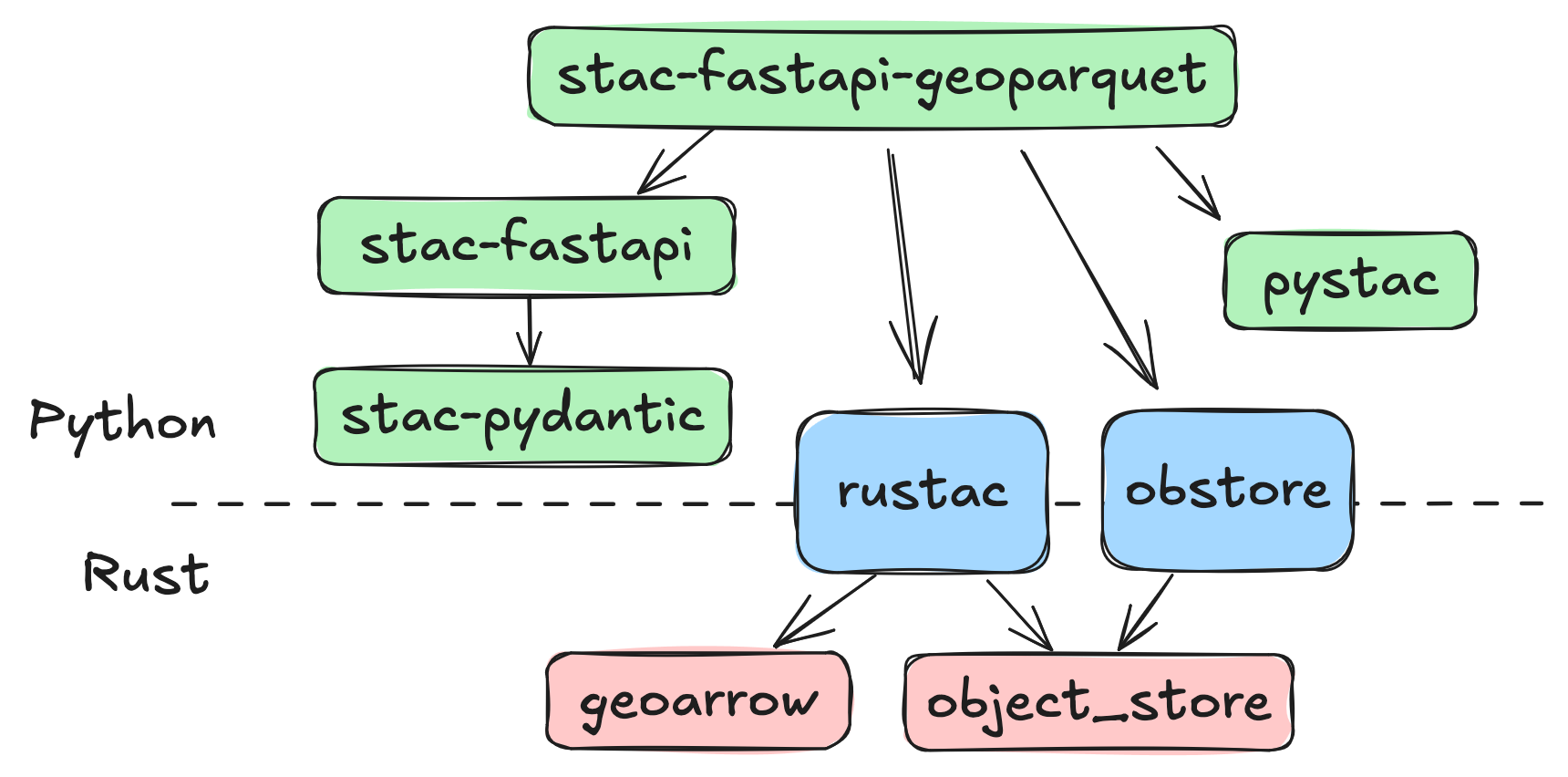
Software
How scale?
🦆
copy
(select *, year(datetime) as year from read_parquet('source/**/*.parquet', union_by_name=true))
to
'destination' (format parquet, partition_by (year), overwrite_or_ignore);
data lakes
Looking forward

- spec release
- stac-geoparquet-visualizer
- appends
- production
Fin
Thank you for your time
https://www.gadom.ski/presentations/2025-06-06-stac-geoparquet.html