stac-geoparquet organization
The tl;dr: by sorting and paritioning stac-geoparquet, we can enable fast searching on the sorted attribute.
Background
stac-geoparquet is a community data storage specification for storing STAC items in geoparquet. We recently did some light experiments on converting about ten million ITS_LIVE items, stored as newline-delimited JSON (ndjson), to stac-geoparquet, and published that work as a notebook. That notebook has some helpful context on the data we're using in this blog post.
The datasets
We're curious if there's more we can do to organize the stac-geoparquet to make searches more efficient. We created three versions of our its-live dataset:
- its-live is the original ndfiles converted to stac-geoparquet with no other modifications
- its-live-partitioned is hive partitioned by year, but otherwise the data are unchanged from the source
- its-live-partitioned-sorted has two changes:
- Each item's
idhas been prefixed with its datetime - Items are sorted by
id(and therefore, by datetime)
- Each item's
We've included the incantation used to create the partitioned and sorted datasets in the appendix. These each live on AWS s3 in a requester-pays bucket, and they're all between 3GB and 5GB in size:
- s3://stac-fastapi-geoparquet-labs-375/its-live/
- s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned/
- s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned-sorted/
The labs-375 suffix is due to the origins of some of this work as a Development Seed internal labs project.
DuckDB
We fired up DuckDB to see how our queries change, if at all, for each dataset.
If you're running this locally, you'll want to make sure your AWS environment is set up to allow requester-pays and the region is set to us-west-2.
To make sure our analysis isn't thrown off by local caching, disable the external file cache.
D set enable_external_file_cache=false;
I'm running all these experiments on a pretty slow wifi connection, so you might have faster times if you try things on a better connection.
A needle in a haystack
Our theory is that stac-geoparquet is at its worst relative to a database when you're looking for a single item by a "commonly indexed" attribute, such as id. We've intentionally picked an ID in the middle/end of the dataset in one of the larger partitions.
First, let's explore what it takes to search by id on the non-partitioned dataset.
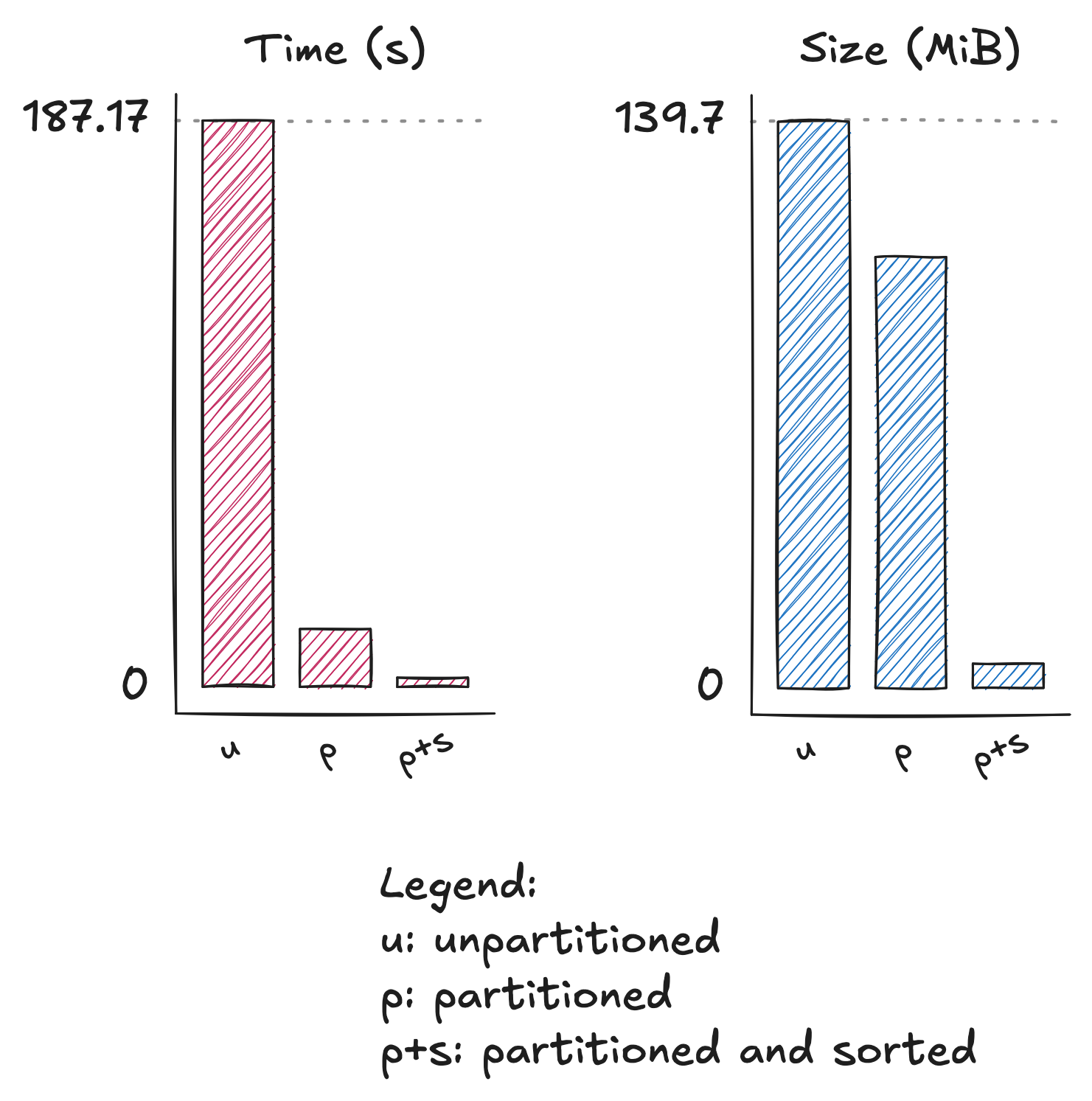
explain analyze select id from read_parquet('s3://stac-fastapi-geoparquet-labs-375/its-live/**/*.parquet') where id = 'LE07_L1GT_116115_20081215_20200912_02_T2_X_LE07_L1GT_114115_20090118_20200912_02_T2_G0120V02_P097';
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ HTTPFS HTTP Stats ││
││ ││
││ in: 139.7 MiB ││
││ out: 0 bytes ││
││ #HEAD: 0 ││
││ #GET: 6284 ││
││ #PUT: 0 ││
││ #POST: 0 ││
││ #DELETE: 0 ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 187.17s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ READ_PARQUET │
│ │
│ Projections: id │
│ │
│ Filters: │
│id='LE07_L1GT_116115_200812│
│15_20200912_02_T2_X_LE07_L1│
│GT_114115_20090118_20200912│
│ _02_T2_G0120V02_P097' │
│ │
│ Total Files Read: │
│ 5134 │
│ │
│ 1 Rows │
│ (2011.46s) │
└───────────────────────────┘
Not awesome.

Partitioning
Does partitioning help?
explain analyze select id from read_parquet('s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned/**/*.parquet') where id = 'LE07_L1GT_116115_20081215_20200912_02_T2_X_LE07_L1GT_114115_20090118_20200912_02_T2_G0120V02_P097';
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ HTTPFS HTTP Stats ││
││ ││
││ in: 106.3 MiB ││
││ out: 0 bytes ││
││ #HEAD: 0 ││
││ #GET: 166 ││
││ #PUT: 0 ││
││ #POST: 0 ││
││ #DELETE: 0 ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 19.12s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ READ_PARQUET │
│ │
│ Projections: id │
│ │
│ Filters: │
│id='LE07_L1GT_116115_200812│
│15_20200912_02_T2_X_LE07_L1│
│GT_114115_20090118_20200912│
│ _02_T2_G0120V02_P097' │
│ │
│ Total Files Read: 44 │
│ │
│ 1 Rows │
│ (185.05s) │
└───────────────────────────┘
A little less download, and a lot faster!
Partitioned and sorted
How about if we search in the sorted dataset? Note that we have to tweak the ID, since we prepended the datetime.
explain analyze select id from read_parquet('s3://stac-fastapi-geoparquet-labs-375/its-live-partitioned-sorted/**/*.parquet') where id = '2008-12-31T19:26:47Z-LE07_L1GT_116115_20081215_20200912_02_T2_X_LE07_L1GT_114115_20090118_20200912_02_T2_G0120V02_P097';
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ HTTPFS HTTP Stats ││
││ ││
││ in: 6.0 MiB ││
││ out: 0 bytes ││
││ #HEAD: 0 ││
││ #GET: 45 ││
││ #PUT: 0 ││
││ #POST: 0 ││
││ #DELETE: 0 ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 3.09s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ READ_PARQUET │
│ │
│ Projections: id │
│ │
│ Filters: │
│ id='2008-12-31T19:26:47Z │
│-LE07_L1GT_116115_20081215_│
│20200912_02_T2_X_LE07_L1GT_│
│114115_20090118_20200912_02│
│ _T2_G0120V02_P097' │
│ │
│ Total Files Read: 44 │
│ │
│ 1 Rows │
│ (25.14s) │
└───────────────────────────┘
So much better!
The takeaway
Sorting and partitioning can be huge for enabling needle-in-a-haystack queries for large stac-geoparquet datastores.
Appendix
The incantation to create the partitioned dataset:
copy
(select *, year(datetime) as year from read_parquet('its-live/**/*.parquet', union_by_name=true))
to 'its-live-partitioned' (format parquet, partition_by (year));
The incantation used to create the sorted dataset:
copy
(select * from
(select * replace concat_ws('-', strftime(datetime, '%Y-%m-%dT%H:%M:%SZ'), id) as id from read_parquet('its-live-partitioned/**/*.parquet'))
order by id)
to 'its-live-partitioned-sorted' (format parquet, partition_by (year));